1/6 · The Same Model, Opposite Results: Context Is the Variable
Same model, same stack, opposite outcomes: +67% vs -19%. The variable isn't the AI. It's context engineering, and Princeton research explains exactly why.
Context Engineering, a six-part series. You’re reading part 1: the science. Part 1: the science (you are here) · Part 2: the discipline · Part 3: the tooling · Part 4: the roles · Part 5: the team · Part 6: the portability
| The paradox | Same model, same stack: one team ships +67%, another slows -19% |
| The cause | Context rot. LLM accuracy degrades as the window fills, by design |
| MECW | The effective window runs well below the advertised one. A managed 128K beats an unmanaged 1M |
| The shift | Prompt engineering is one request. Context engineering is the whole system |
| Two pressures | Quality (context rot) and cost (tokens) pull in opposite directions |
Anthropic reported a 67% increase in pull requests merged per engineer per day after rolling Claude Code out across its engineering org. Around the same time, METR ran a randomized controlled trial on experienced open-source developers (arXiv:2507.09089) and found AI-assisted work made them 19% slower. Same category of tool, same year, results pointing in opposite directions.
I spent a long time assuming that gap came down to skill, or model choice, or the subscription tier. It doesn’t. The METR developers were dropping a capable agent into a cold context every morning and starting from zero. The Anthropic teams had built a system around what the model sees, when, and in what shape. The variable that separates +67% from -19% is the architecture of the context, not the intelligence of the model.
That’s the part nobody puts on a slide: the model is rarely the bottleneck, what you load into it is.

What context rot actually is
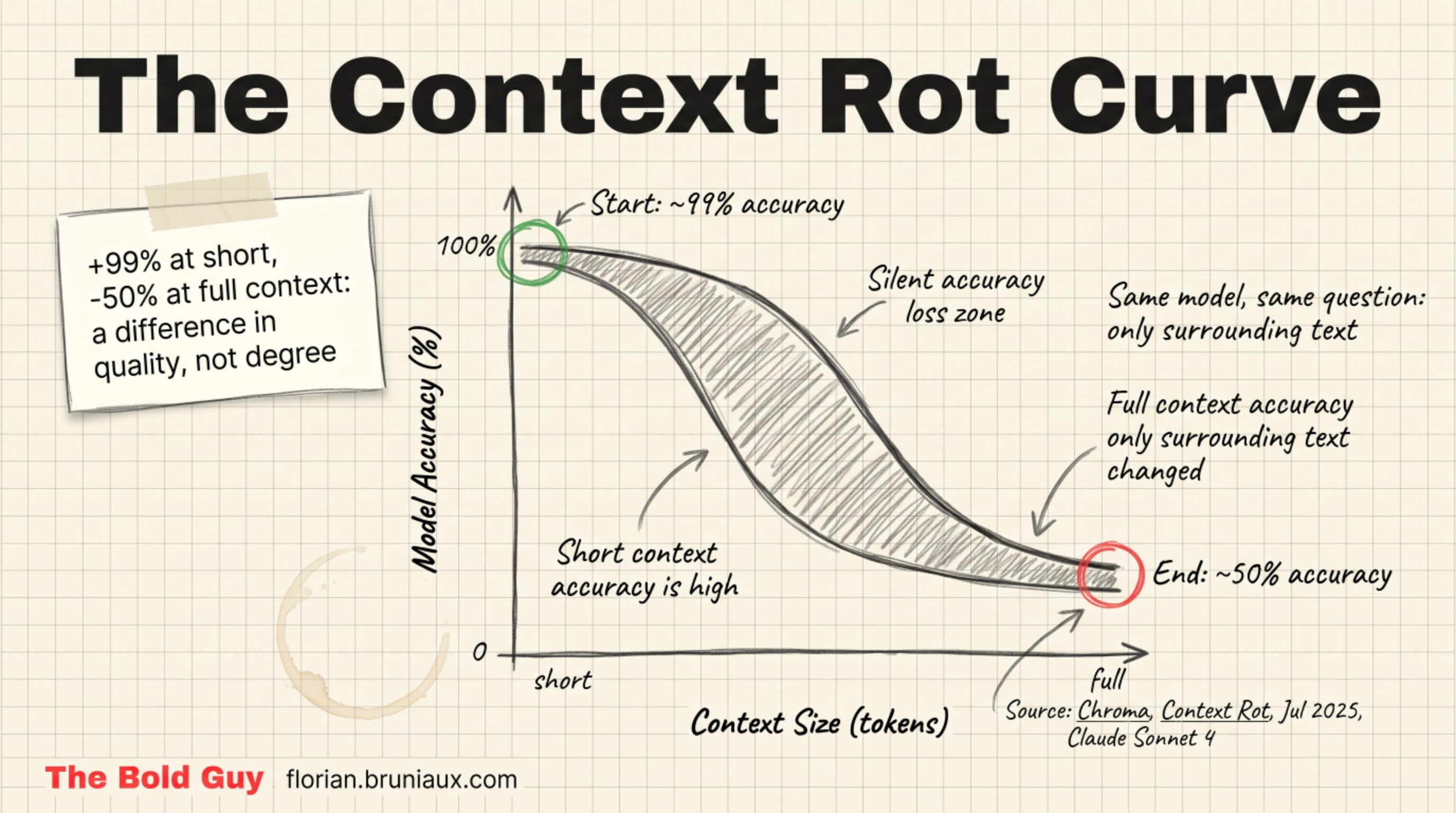
In July 2025, Chroma Research published a study on 18 frontier LLMs that named something a lot of us had felt without measuring. They called it context rot: as the input context grows, model accuracy drops, even on tasks the same model handles perfectly at short length.
The pattern is blunt. On retrieval tasks that models handle almost perfectly at short context, accuracy slides as the window fills, dropping tens of points on the harder setups by the time the context is full. Same model, same question, same answer sitting in the window. The only thing that changed was how much surrounding text the model had to attend to.
This is not a bug that a patch fixes. It’s a property of how transformer attention works, and it shows up through three mechanisms worth understanding.
The first is quadratic scaling. Attention computes relationships between every pair of tokens, so doubling the context roughly quadruples the work. At 200K tokens the model is spreading its attention across billions of pairwise relationships, and that attention gets thinner everywhere.
The second is lost-in-the-middle. Liu et al. at Stanford (TACL 2024, arXiv:2307.03172) showed that models systematically underweight information placed in the middle of a long context. They attend well to the beginning and the end, and the material in between gets the least attention. Put your critical instruction in the middle of a 100K dump and the model technically has it, but barely.
The third is that degradation starts earlier than the marketing implies. For some models the slide begins within the first 10 to 20K tokens, and on a 200K window accuracy can already be slipping well before you’ve filled a quarter of it. The window is advertised as 200K. The part where the model stays sharp is a fraction of that.
Why a managed 128K beats an unmanaged 1M
The obvious response is to wait for bigger windows. Gemini shipped a million tokens, others are following, and the instinct is to treat window size as the problem that scale will solve.
That instinct is wrong, and there’s a name for why. The Maximum Effective Context Window (MECW) is the share of the advertised window a model can actually use before accuracy falls apart, and research measuring it (arXiv:2509.21361) found that share often runs far below the number on the box, dropping fast as the task gets harder. Retrieval benchmarks at the extreme end make the point: on a 1M-token needle test, Opus 4.6 dropped from 93% accuracy at 256K to 76% at 1M, and Sonnet 4.5 landed near 18.5% at 1M. The model can technically read every token. It does not weight them equally, and the degradation scales with the size of the mess you hand it.
The conclusion is uncomfortable but clean. A 128K window with well-engineered context outperforms a 1M window stuffed with stale, loosely relevant content on most real tasks. A bigger window buys capacity. It does not buy quality. The teams that will use 1M windows well are the same teams that manage 128K windows well today, because window size and context discipline are two different axes and one never substitutes for the other.
One production pattern that makes this concrete: on IFTTD, Quentin Adam described routing large-context tasks to a high-capacity model for execution while keeping a reasoning model in the orchestration role, switching when the codebase exceeds what the orchestrator can reliably handle (ep 341). Bigger window for the execution layer, tighter focus for the reasoning layer. The discipline of managing what each model attends to does not dissolve at scale.

Prompt engineering versus context engineering
Tobi Lütke pushed the term into wide use in mid-2025, and Andrej Karpathy amplified it with a working definition: the art of filling the context window with the right information at the right time. The phrase went through the usual hype cycle, got mocked, got overused, and landed somewhere genuinely useful, the same arc prompt engineering travelled a year earlier.
The distinction between the two is a difference in kind, not degree.
| Prompt engineering | Context engineering | |
|---|---|---|
| Scope | One request | A session or a system |
| Lifespan | Single interaction | Persists across interactions |
| Effort | Crafted per request | Designed up front |
| Artifact | A prompt string | A configuration system |
Prompt engineering is scribbling a good note to a contractor. Context engineering is the onboarding, the style guide, the architecture docs, and the team norms that make the contractor understand the project before they read a single note. One is a sentence. The other is a building. Prompt engineering is a subset of context engineering, and most teams stuck on output quality are crafting better sentences when their actual problem is that they never constructed the building. One counterintuitive consequence of that gap: deploying a more capable model into the same underbuilt context can actively make results worse. On the French tech podcast IFTTD, Guillaume Laforge described a “mansplaining” effect where a sufficiently capable model ignores injected context and generates from its training priors instead, producing confident but contextually wrong answers (ep 361). The full discipline, its budget, its hierarchy and its lifecycle, sits in the guide’s context engineering reference.

Two pressures pulling in opposite directions
Once you accept that context is the variable, you find yourself managing two forces that work against each other.
The first is context rot, the quality pressure. Too much content in the window dilutes attention and the model gets vaguer, more inconsistent, more prone to ignoring the rules you set early. The fix is to cut: prune, scope, compact.
The second is token cost, the economic pressure. Every token you send is billed, every session has a budget, and waste accumulates quietly. This is the FinOps side of the discipline, and it pushes toward the same behavior from a different motive: send less.
Between the two sits the idea of Minimum Viable Context: give the model exactly what it needs for the task in front of it, nothing more. Undershoot and the model hallucinates or produces something generic, because it lacks the information to do better. Overshoot and the model drowns in noise, its attention spreads thin, and adherence to your rules drops. The interesting part is that these two pressures point the same way more often than people expect. Cutting tokens doesn’t only save money. It measurably reduces hallucination and the overthinking a model does on simple requests, because a shorter, sharper context produces more grounded answers. Less context, better output, not just a cheaper one.

That tension is why the rest of this series splits in two directions. Managing the quality pressure is a discipline question: how you write, scope, and verify your configuration so the model stays accurate over months, not just on day one. Managing the cost pressure is a tooling question: which layer of the stack you filter, and what the ecosystem of token-reduction tools actually does. Both start from the same diagnosis you’ve just read.
What to do with this
Three things are worth doing before you touch a single tool.
Watch your own degradation: next time a long session starts producing inconsistent or off-spec output, notice when it began. In my experience it tracks with the context filling past roughly 75%, not with the model getting dumber.
Stop chasing window size: if a task is failing, the answer is almost never “wait for a bigger context window.” It’s “give this model less, but more relevant.”
Separate the two pressures: decide whether your current pain is quality (the model drifts, ignores rules, goes stale) or cost (the bill climbs, sessions hit limits). They need different fixes, and conflating them is how people end up optimizing the wrong layer.
The next article goes after the quality pressure directly: a maturity model for context configuration, why a CLAUDE.md that works on day one starts lying about your project three months later, and the verification loop that catches it. The third maps the tooling: four layers of token reduction, the tools that live in each, and the blind spot that affects everyone on a Max or Pro subscription.
From the field, via IFTTD episode transcripts: Guillaume Laforge, ep 361 on model capability vs context grounding; Quentin Adam, ep 341 on multi-model orchestration by context-window size.
If you’ve watched the same model give your team and another team opposite results, I’m curious what you think the variable was. Tell me where this matches what you’ve seen and where it doesn’t.
Talked about in
Where I covered this live or on a podcast.