2/6 · The CLAUDE.md That Doesn't Lie After Three Months
A good CLAUDE.md on day one is easy. Keeping it accurate three months later is the hard part. Maturity model L0 to L5 with a drift-detection loop.
Context Engineering, a six-part series. You’re reading part 2: the discipline. Part 1: the science · Part 2: the discipline (you are here) · Part 3: the tooling · Part 4: the roles · Part 5: the team · Part 6: the portability
| The trap | A CLAUDE.md that works on day one degrades silently. Adherence slides from near-total to mediocre over months |
| The measure | Adherence is real and observable. It falls with file size and rule count |
| The model | Six levels, L0 amnesia to L5 infrastructure. Most teams sit at L1 |
| The lever | Path-scoping cuts always-on context 40-50% with zero coverage loss |
| The proof | Two lines at the top of the file tell you if Claude even loaded it |
Three symptoms show up in every team that has run an AI coding agent for more than a few weeks.
The session that drifts. Claude starts hallucinating imports after thirty minutes of work, and the instinct is to blame the model having a bad day. The real cause is mechanical: the rules from your CLAUDE.md got pushed out of the active context window by thirty minutes of tool output, and the model is now working without them.
The code that’s stale. Claude keeps generating against the old API three sprints after you migrated. The model isn’t wrong, exactly. The CLAUDE.md is. Nobody updated it, so it’s lying about the current state of the project, and the model is faithfully following the lie.
The degradation nobody sees. Rule adherence slides from near-total to middling over a couple of months, with no signal, no alert, no moment where it breaks loudly. It just gets a little worse every week until someone notices the output has been mediocre for a while.
A good CLAUDE.md on day one is the easy part. Stopping it from lying about your project three months later is where the whole thing actually plays out. The first part of this series (the science of why context degrades) explained the pressure. This one is about the discipline that holds the line against it.
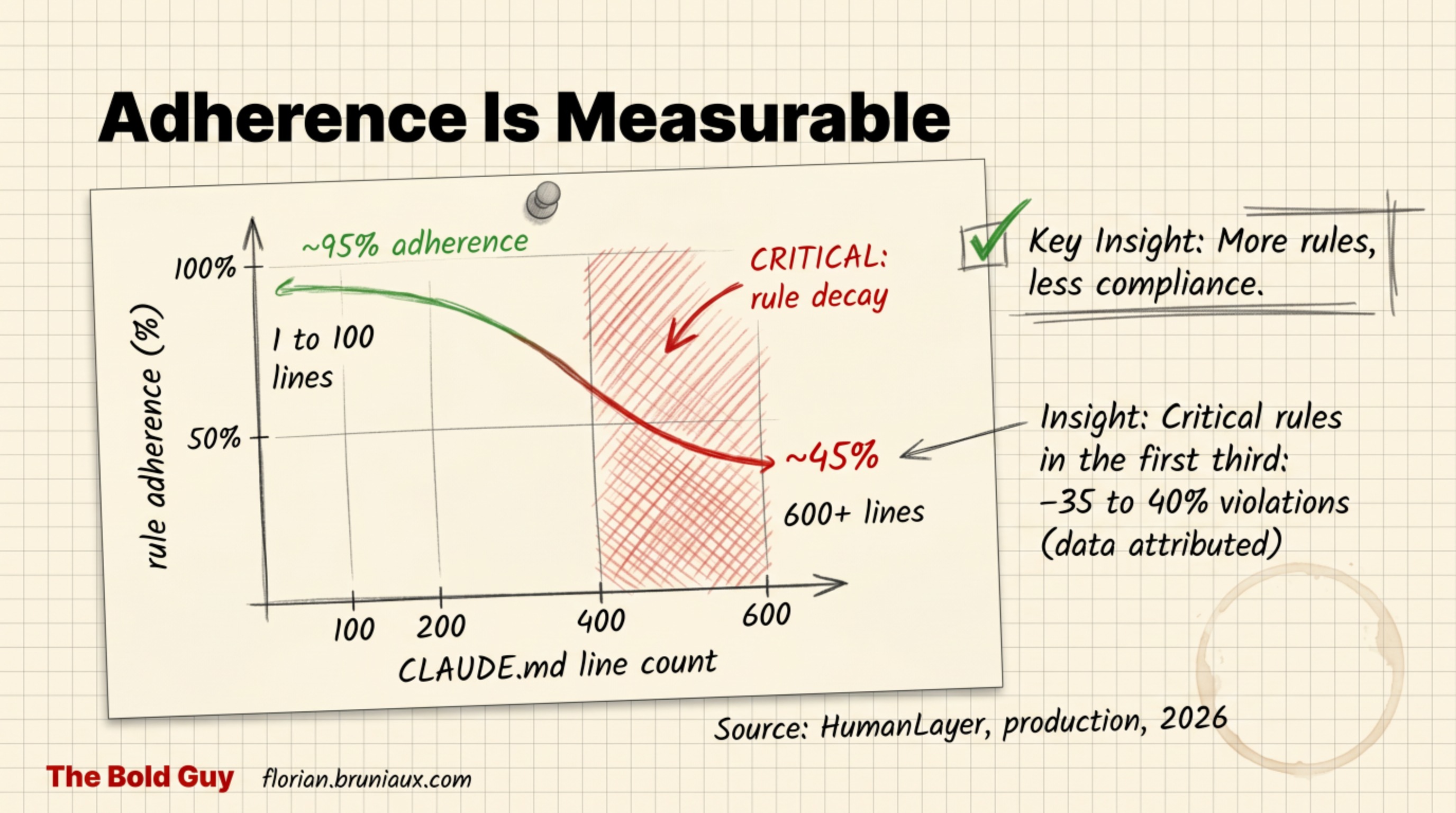
Adherence is measurable
CLAUDE.md quality is not a matter of taste. It’s observable, and what teams observe is unkind to the “dump every rule you can think of” approach.
HumanLayer, running agents in production, landed on a blunt rule from watching adherence degrade: keep instruction files short, a few hundred lines at most, and ideally far less. The pattern is the one everyone feels. A short file gets followed closely. The longer it grows, the more rules the model quietly drops, and you don’t get to choose which ones. The mechanism is the same context rot from part one: a model spreading attention across hundreds of loosely relevant constraints spends more of its capacity filtering than reasoning. There’s a practical ceiling somewhere around 150 distinct rules where selective forgetting kicks in.
Order matters too. Putting the critical rules in the first third of the file measurably cuts violations, purely from position. Same rules, different placement, better adherence. That’s lost-in-the-middle working for you instead of against you.
And the source of the file matters more than people expect. Gloaguen et al. at ETH Zürich (2026, across 138 benchmarks and 12 repos) compared agent config files written by hand against ones generated by an LLM. The hand-written files improved task success by about 4%. The LLM-generated ones reduced success by about 2% while adding roughly 20% to inference cost. Generating your CLAUDE.md with the model it’s meant to guide is worse than writing nothing.
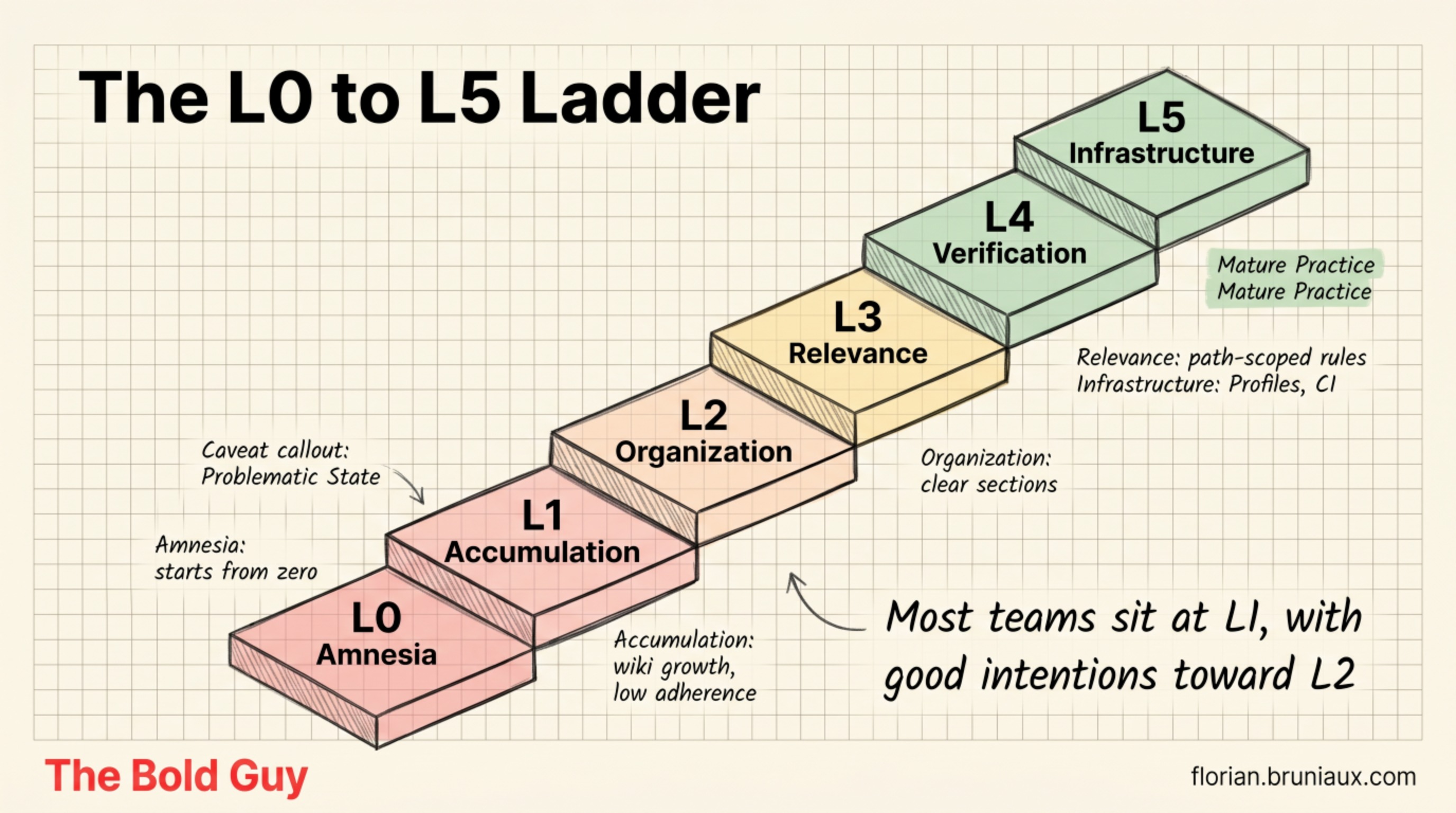
A maturity model, L0 to L5
After ten months building a production SaaS on Claude Code, with a team of four, the same arc kept repeating. Over that period, 445 non-merge commits of 2,811 total touched AI configuration files, roughly 16% of the activity. When one commit in six touches AI config, you are not tuning a setup preference, you are maintaining infrastructure. The arc maps cleanly onto six levels. It comes from production, not a whiteboard, and most teams sit lower than they think. The guide’s context engineering reference carries the same L0 to L5 model with the operational detail each jump needs.
L0, amnesia. No CLAUDE.md. Claude starts from zero every session, re-learns the project every morning, and forgets it every night. This resembles the METR setup from part one, a capable agent dropped into a cold context each time.
L1, accumulation. A CLAUDE.md exists and grows. It’s the team wiki where everyone adds a rule and nobody removes one. Useful, well-intentioned, and on a direct path to the 600-line adherence cliff.
L2, organization. Sections appear. Global rules get separated from project rules. The file is readable. But it’s still one undifferentiated config loaded in full for every task, whether you’re touching the database or editing CSS.
L3, relevance. Path-scoping arrives. Rules activate only when the files of their domain are in scope. The backend rules don’t exist in the window while you’re in the frontend. This is the first level where the file size problem stops being a problem.
L4, verification. You stop assuming the config loaded and start proving it. A canary check confirms, at session start, that Claude actually read the file.
L5, infrastructure. Profiles in YAML generate the configs. A sync command keeps them aligned across tools. CI fails if they drift. Context configuration is now versioned, reviewed, and enforced like any other part of the codebase.
Ask where your team sits right now. Then ask where your last client engagement sat. The honest answer for most is L1, with a few good intentions toward L2. The clearest signal of where the field sits: the most-starred CLAUDE.md on GitHub, claude-token-efficient, holds more than 5,700 stars for a single text file with terse instructions. People feel the pain and bookmark the closest thing to a fix.
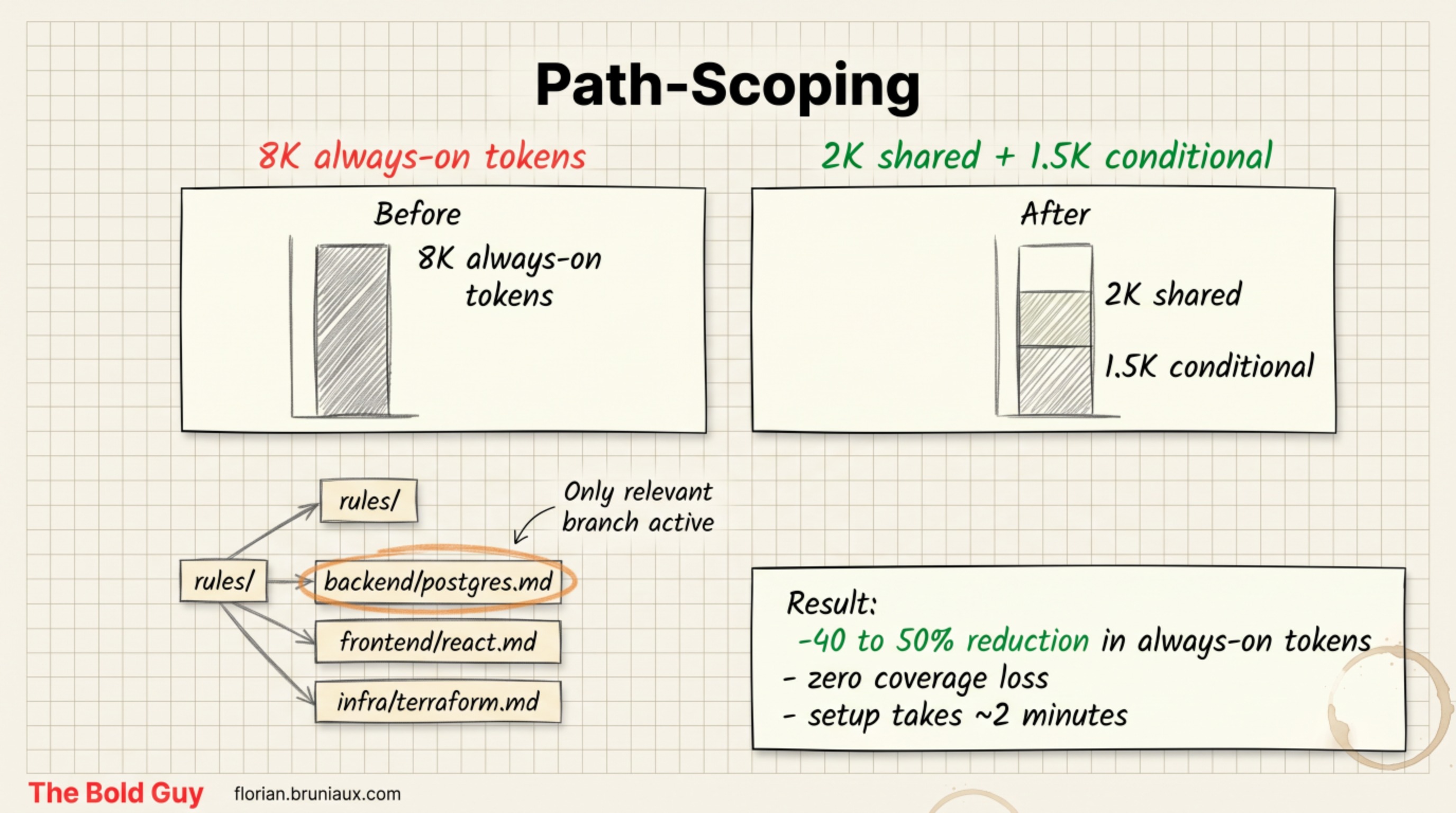
Path-scoping in practice
L3 is the single highest-leverage move, so it’s worth showing concretely. Instead of one root CLAUDE.md carrying every rule, you split domain rules into a directory.
rules/
backend/postgres.md # loaded only when backend files are in scope
frontend/react.md # loaded only when frontend files are in scope
infra/terraform.md # loaded only when infra files are in scopeWhen Claude is working in /components/, the PostgreSQL conventions and the Terraform rules do not exist in its window. They aren’t deprioritized, they’re absent, which means they cost nothing and dilute nothing.
In production at Méthode Aristote, this cut always-on context by 40 to 50% with zero loss of coverage. The concrete shape: a setup that carried 8K tokens of always-on rules dropped to around 4K of genuinely shared rules, with the domain-specific rest loaded only when its part of the codebase is in scope. Setting up the rules/ directory took about two minutes. The result is that Claude’s working memory is larger by the time you hand it a real task, which is exactly the lever part one argued for.
Rules versus skills
There’s a related distinction that trips up a lot of configs. Rules are always-on constraints, loaded every session. Skills are on-demand procedures, where the model decides for itself whether the procedure is relevant to the current task.
The mistake is putting procedures into rules. A 50-line onboarding procedure in CLAUDE.md gets loaded even when you’re writing CSS. It’s useful exactly once, on someone’s first day, and then it’s dead weight in the context of every session for the next three months. That’s a real pattern I flagged for consulting teams: mission onboarding blocks of 50 to 80 lines sitting in the root CLAUDE.md, paid for on day one and then carried, uselessly, for the other 89 days of the engagement.
The rule of thumb: if it’s a constraint that should hold on every task, it’s a rule. If it’s a procedure the model runs occasionally, it’s a skill, and it should load only when invoked.
CLAUDE.md is one kind of memory, not the only one
Here is a failure I have run three times. Same codebase, same prompt, “set up the auth middleware,” three different sessions on three different days. One session built JWT with Redis. One built session cookies with no Redis. One built JWT again, with a different expiry strategy. None of them is wrong. All three are inconsistent, because each session started with no memory of the decisions the previous ones had already made.
CLAUDE.md solves part of this. It carries always-on rules, the constraints that should hold on every task in a directory. It is the wrong place for two other kinds of memory, and trying to cram them in is half of why files cross the adherence cliff.
Architectural decisions belong in a decision store, queried when relevant rather than carried every turn. A persistent decision-store MCP, like the doobidoo memory server, exists for exactly this. “We chose Pusher over SSE because WebSockets fail behind some corporate proxies” is a decision with a non-obvious reason. Recorded once, it resurfaces six months later in a different project the moment SSE comes up again, so nobody relitigates it from scratch.
Code and docs belong in retrieval, not in the window. Serena handles symbol navigation, grepai does semantic code search, Context7 pulls versioned library docs. The model fetches what it needs on demand instead of you pasting files it will mostly skim.
The split is worth keeping in your head. CLAUDE.md: this rule applies to every session here. The decision store: something we decided three projects ago. Retrieval: code and docs the model fetches only when the task touches them. The full memory stack, from native to cross-session to team-shared, is laid out in the guide’s memory systems reference.
Verification and the loop
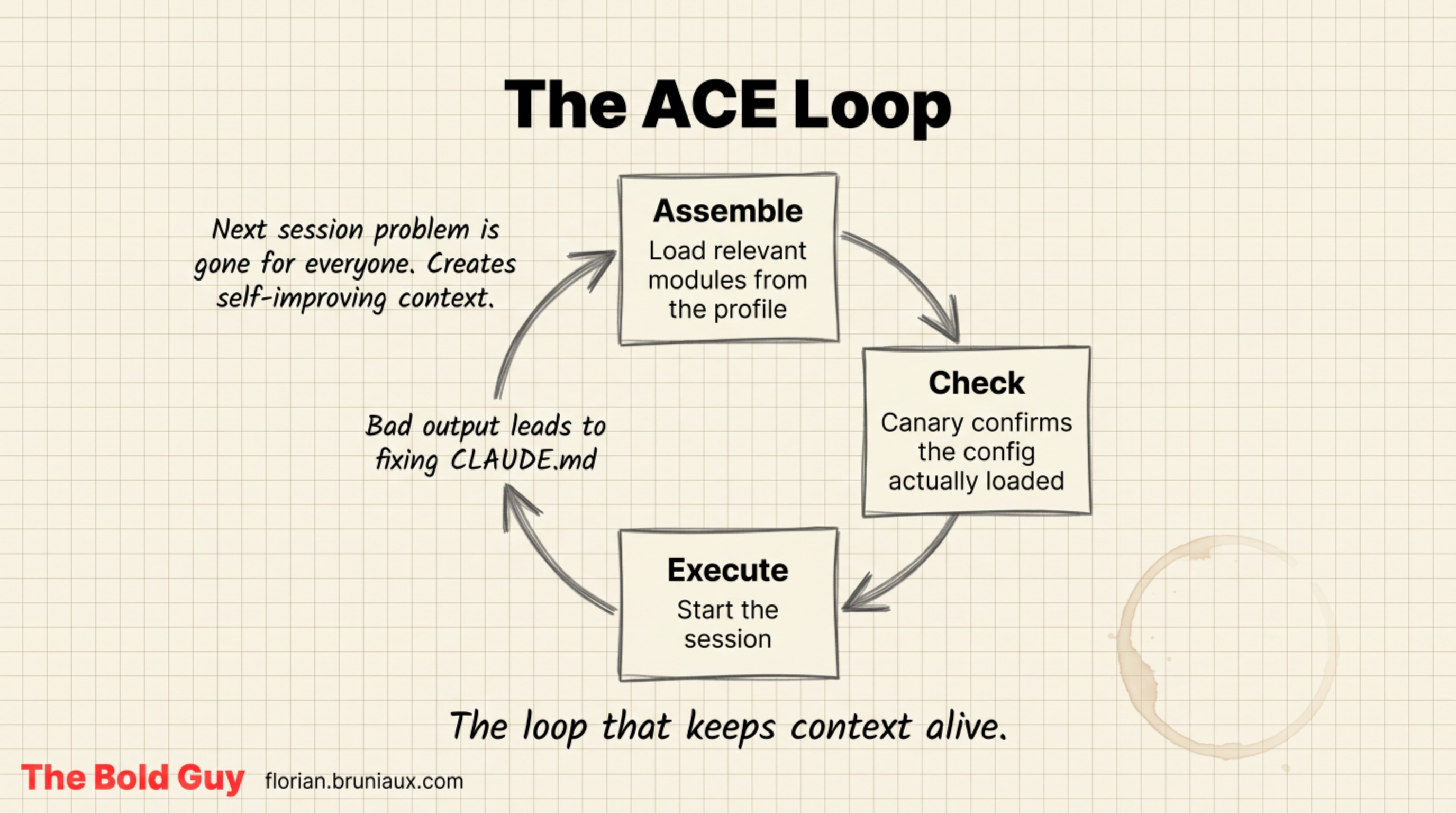
L4 is where this stops being configuration and starts being engineering, because it introduces proof.
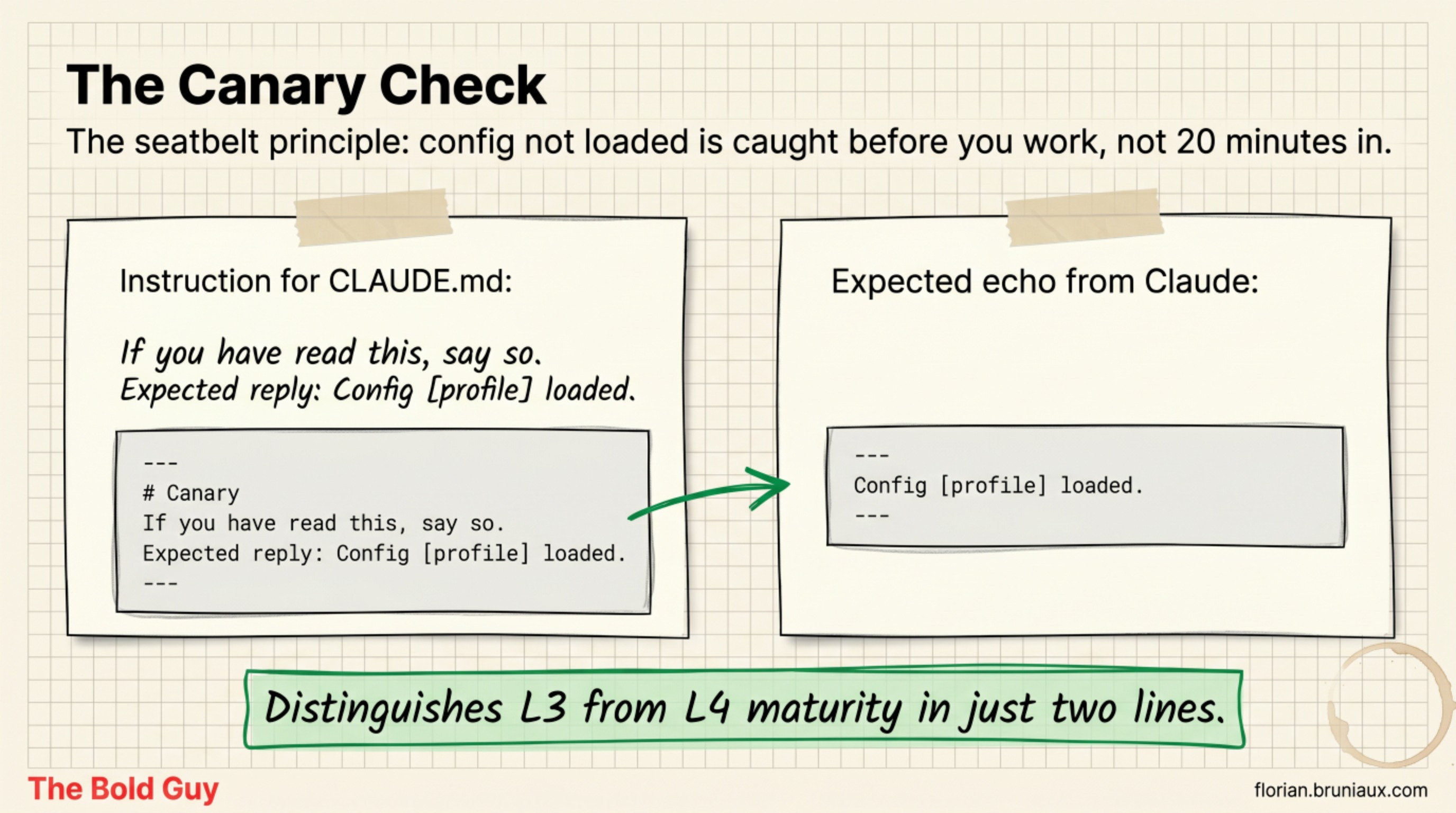
The canary check is two lines at the top of CLAUDE.md that Claude must echo back at the start of a session. Something like a line that says “if you’ve read this, say so,” and a line that defines the exact phrase to return. If Claude doesn’t repeat them, the config didn’t load, and you know that before you start working instead of twenty minutes in, wondering why the behavior doesn’t match the rules you carefully wrote.
The analogy I use: L3 is putting on the seatbelt. L4 is the dashboard light confirming the seatbelt is actually buckled. One is a hope, the other is a signal.
Practitioners shipping agents in production reach the same conclusion from the reliability side. On IFTTD, Zineb Bendhiba described running continuous non-regression tests for agent behavior with explicit pass-rate thresholds, because correct behavior at launch drifts silently without ongoing measurement (ep 326). Frédéric Barthelet extended that to a statistical framing: for non-deterministic systems, the right verification method replays key scenarios ten to a hundred times in parallel and measures a success rate rather than expecting a single deterministic result (ep 329). The canary check is a lightweight instance of that same principle.
L5 closes the loop. The ACE loop reframes every bad output: it’s not an incident to fix once, it’s a bug report against the context. You reproduce it, find the cause in CLAUDE.md, fix the file, and verify it doesn’t recur. Profiles make this scale. One YAML file per role or developer (the guide breaks down what those role profiles contain), and a sync command (pnpm ai:sync) regenerates CLAUDE.md, the Cursor rules, and the Copilot instructions from that single source. The convention lives in one place. The three configs regenerate in seconds. CI fails the build if they drift apart.
The payoff is concrete. When that loop ran a deliberate context cleanup in production, a process we called the Context Diet, the always-on config went from 2,518 lines to 646, a 74% cut, and our internal context quality score (a /120 rubric) went from 90 to 100. Less context, better results, exactly the counter-intuitive finding from part one.
The same discipline made a 243-file React migration trivial: 24 agents, around ten files each, 240 files merged automatically and 3 sent to human review, a 1.2% exception rate, finished in about an hour against a three-day projection. The mechanism is worth copying. An Opus planner ran read-only, no writes and no execution, which forced it to produce a complete brief.md spec before anything moved. Each of the 24 agents then ran in its own git worktree, so a broken agent could not touch the others, and the shared brief carried the context none of them would otherwise have had. None of that works without a context the agents can trust.
Honest limits
This discipline has failure modes, and pretending otherwise is how people over-build.
Over-engineering is a real failure mode. A solo developer on a small project does not need profiles, sync, and CI gates. L2 with a little path-scoping is plenty, and reaching for L5 too early is its own kind of waste.
Context poisoning is the subtle one. A small hallucination works its way into CLAUDE.md, a fake convention or a wrong reference, and from then on it drifts every session silently. It’s more insidious than ordinary context rot because the output looks correct. This is the same reason you never let the model generate its own config: you’re laundering a hallucination into a permanent instruction.
And there’s a ceiling on the whole thing. As Birgitta Böckeler put it in her context engineering for coding agents piece on martinfowler.com, there are no unit tests for context engineering. You can measure adherence, you can run canary checks, you can score your config, but you cannot prove correctness the way you prove a function correct. This is a discipline of reducing uncertainty, not eliminating it, and treating it as exact is its own trap.
What to do this week
Three moves, in order of leverage.
Run wc -l CLAUDE.md. Past 200 lines, adherence is already degrading: individual rules start competing for attention. Past 600 lines, the file stops working as rules and becomes background vibe. Either way, the fix is the same: find three sections that only apply to one part of the codebase and move them into a rules/ directory. That’s L3, and it takes a few minutes.
Cut the procedures: anything that reads like a runbook or an onboarding sequence should be a skill, not a rule. Pull it out of the always-on file.
Add the canary check. Two lines at the top, a phrase Claude echoes back. Now you know, every session, whether your config actually loaded. That’s the cheapest L4 you’ll ever buy.
The third article in this series leaves the configuration question and goes after cost: the four layers of token reduction, the tools that live in each one, and the blind spot that hides spending from everyone on a Max or Pro subscription. It covers the same discipline from the cost side, once you’ve handled the quality side here.
From the field, via IFTTD episode transcripts: Zineb Bendhiba, ep 326 on behavioral non-regression testing; Frédéric Barthelet, ep 329 on statistical CI/CD for non-deterministic systems.
If your CLAUDE.md has ever lied to you about the state of your own project, I’d like to hear how you caught it, and how long it took.
Talked about in
Where I covered this live or on a podcast.