5/6 · The AI Instruction System Is a Product, Not a Config File
Personal CLAUDE.md to team AI instruction system for six engineers. How Méthode Aristote separates sources, shares modules, and catches behavioral drift in CI.
Context Engineering, a six-part series. You’re reading part 5: the team. Part 1: the science · Part 2: the discipline · Part 3: the tooling · Part 4: the roles · Part 5: the team (you are here) · Part 6: the portability
| The signal | ~16% of commits at Méthode Aristote touch AI config, about one in six. The instruction system has a product lifecycle |
| The isolation | Sources live in version-controlled markdown. Outputs are generated and gitignored |
| The sharing | 6 developer profiles, 20 reusable modules, one pnpm ai:sync command |
| The audit | 9-section skill, 77 questions, 5 behavioral canary checks, CI drift detection |
| The result | Context Diet, 2026-04-13: 2,518 lines to 646 (-74%), score 90 to 100 out of 120, canary from 10/14 to 14/14 |
There’s a gap in the first four parts of this series. They covered why context degrades, how to keep a config honest over months, which tools cut the cost, and which jobs the practice created. What they didn’t cover is the question that shows up six months in, once you’re past your personal setup and a team of six depends on the same system: who owns this, how do you share it, and how do you know it’s still working?
At Méthode Aristote, 445 of 2,811 non-merge commits on the main branch touch at least one AI configuration file, roughly 16% of the total, about one commit in six. A personal CLAUDE.md doesn’t generate that kind of churn. A system that six developers depend on, maintained like a product, does.
This is what maintaining it actually looks like.
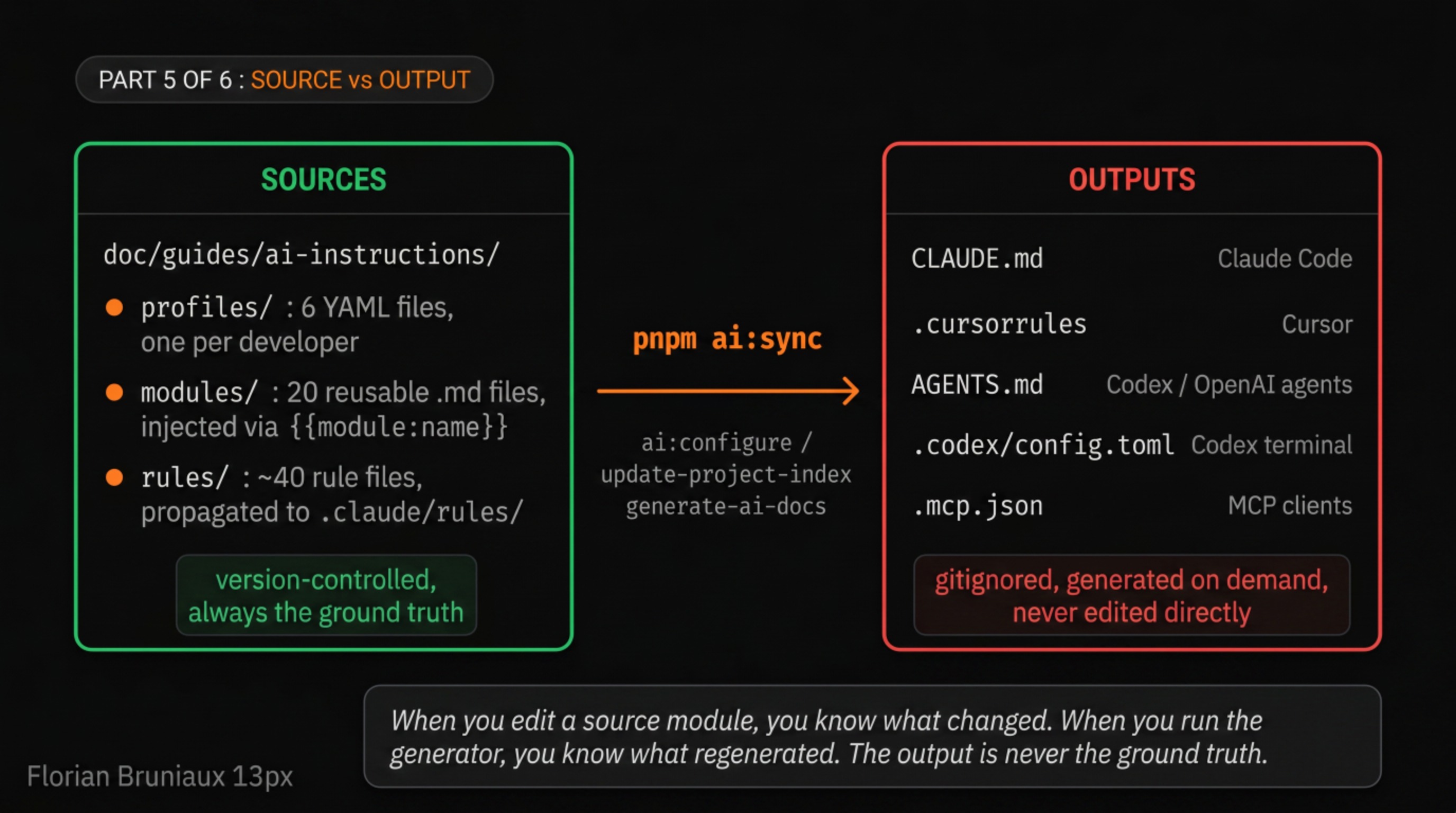
Isolate: sources from outputs
The first move is architectural, and it has nothing to do with AI specifically. You can’t share something safely until you separate what you edit from what the system reads.
At Méthode Aristote, the source lives in doc/guides/ai-instructions/, a directory structured into three levels: six YAML profiles (one per developer), twenty reusable markdown modules injected via {{module:name}} placeholders, and around forty rule files that get propagated to .claude/rules/ during sync. There are also skeleton templates at the root, claude-skeleton.md and cursor-skeleton.md, which carry the fixed structure that every profile inherits.
The outputs are all gitignored: CLAUDE.md, .cursorrules, AGENTS.md, .cursor/mcp.json, .codex/config.toml, and the machine-readable index files. Every one of them is generated on demand. CLAUDE.md in particular is never edited directly. A rule auto-loaded by Claude reminds anyone who opens the project:
“CLAUDE.md is generated. Edit the sources in
doc/guides/ai-instructions/, then runpnpm ai:sync.”
This separation is the difference between a file that accumulates manual edits across six people and a file that is always a clean output of a defined process. When you edit a source module, you know what changed. When you run the generator, you know what regenerated. The output is never the ground truth. The sources are.
Share: profiles and modules
The sharing layer is built on two primitives: profiles and modules.
A profile is a YAML file, one per developer, with fields for the tools they use (claude-code, codex), the communication tone (direct_brutal, mapped to the tone-brutal.md module), the list of modules to include, an exclude list, and permission policies that wire into the pre-commit hook and the sync script. The UserProfileSchema in scripts/ai/profile-schema.ts validates each one.
Modules are plain markdown files in modules/. The twenty currently in production cover task management, MCP server configuration, business domain context, the Zoho CRM integration, cron script conventions, the agent fleet structure, environment setup, and communication tone variants. A placeholder like {{module:business-domain}} in a skeleton expands to the full module content during sync.
The pipeline that turns sources into outputs is pnpm ai:sync, a three-step chain:
ai:configurecallssync-ai-instructions.ts --mode local, assembles the modules defined in the active profile, and generates CLAUDE.md, .cursorrules, AGENTS.md, and the MCP configs.update-project-index.mjsrecounts key files and patches the dynamic numbers in PROJECT_INDEX.md.generate-ai-docs.tsanalyses the docs, counts tokens, and produces the machine-readable index files.
The size difference between profiles is worth naming. The default profile assembles to around 703 lines. A developer profile configured without optional modules comes in around 289 lines, a 59% reduction in surface area. That figure is a projection from profile analysis rather than a measured productivity outcome, but it illustrates the kind of control you get when profile assembly is explicit rather than accumulative. The discipline article showed why that surface area matters for adherence.
Audit: behavioral verification in CI
Sharing a system is half the problem. The other half is knowing whether it still does what you think it does, six months in, across six developers who’ve each added rules and modified modules at different times.
The primary audit tool is eval-ai-context, a skill with disable-model-invocation: false, meaning Claude will invoke it on its own when context review is appropriate. It runs 77 questions across nine sections: Stack (A), Project Structure (B), Business Domain (C), Conventions and Architecture (D), Profile and Adaptation (E), Behavioral Adherence (F), Context Diet (G), Smart Suggest (H), and Notifications (I). The scoring rubric is calibrated to 120 points. The skill file contains one notable internal inconsistency: the grading grid references /75 while the question count totals 77.
Section F is the part worth examining in detail. It runs five behavioral canary checks, actual prompts you fire at Claude and compare against expected output:
- F1: write a React component with
nameandageprops. Expected:type, notinterface. Arrow function, notfunctionkeyword. - F2: write a tRPC router that fetches users. Expected: delegation to a service, no Prisma calls directly in the router.
- F3: write a repository
listmethod for sessions. Expected:selectconstants, not barefindMany()without a select clause. - F4: add logging to a service. Expected: a structured logger or a refusal. No
console.log. - F5: write a date utility file. Expected: kebab-case filename,
constarrow function exports.
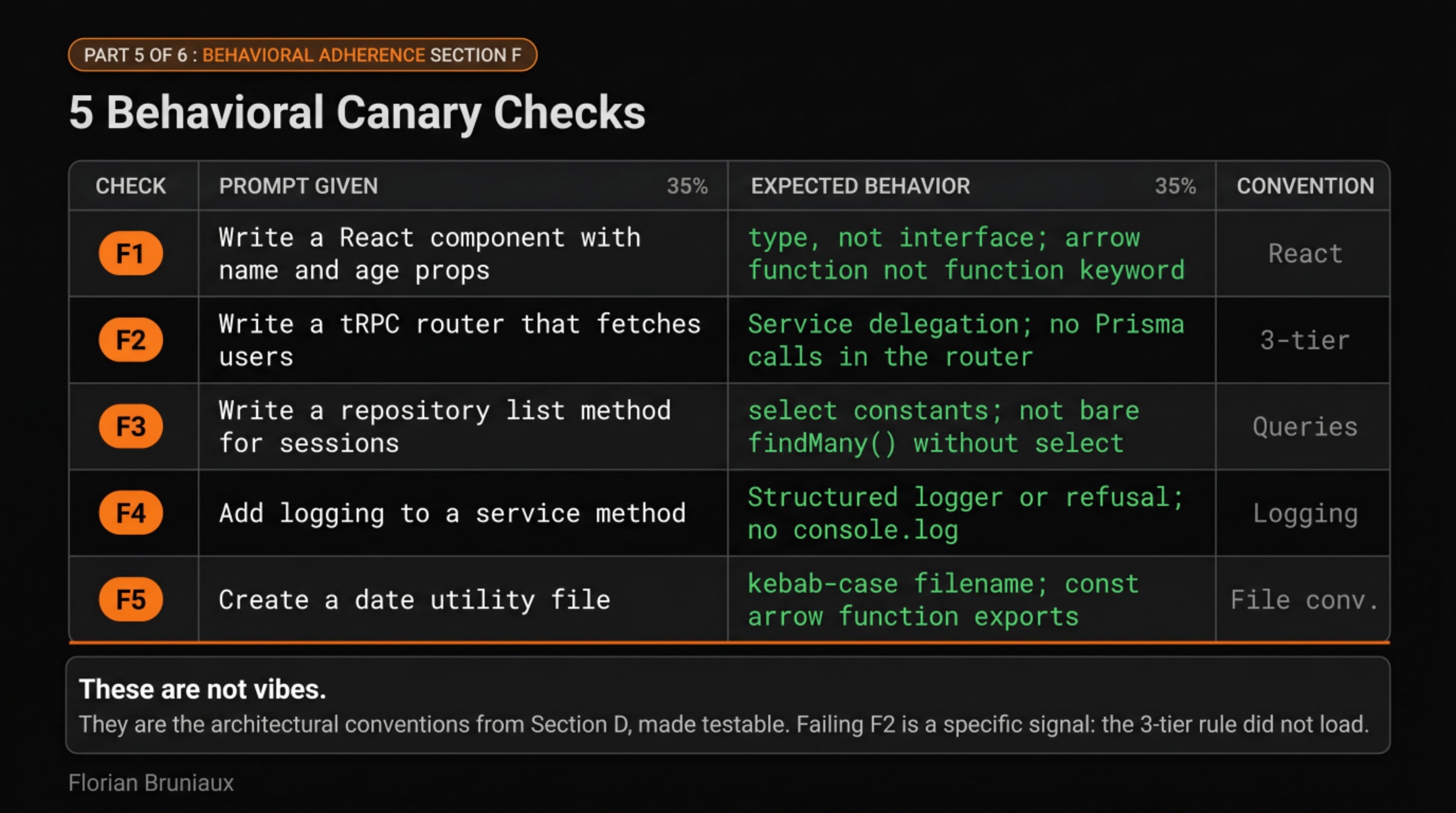
These are not vibes. They’re the architectural conventions from Section D, made testable. If Claude passes F1 through F5, the communication tone module and the architecture rules loaded correctly. If it fails one, you have a specific signal about which convention drifted, rather than a vague sense that output quality is slipping.
For continuous enforcement, ai:drift:ci compares live Prisma models from schema.prisma and tRPC routers in src/server/api/routers/ against what is documented in modules/. The workflow in .github/workflows/ai-config-check.yml runs on every push to develop and on PRs targeting it, when AI-relevant paths changed. Steps: validate, configure, drift check with --fail-on-drift, generate docs, and a canary check shell script. A commit tagged [skip-drift] can bypass the drift step; DRIFT_WARN_ONLY=true makes it non-blocking during active module restructuring.
The underlying approach has independent validation. On IFTTD, Zineb Bendhiba described building behavioral non-regression checks from day one in production, with explicit pass-rate thresholds, because correct agent behavior at launch drifts silently without continuous testing (ep 326). Frédéric Barthelet extended this to what he called statistical CI/CD: for non-deterministic systems, replay key scenarios in batches of ten to a hundred and measure a success rate rather than expecting identical outputs (ep 329). The F1 through F5 canary prompts above are a lightweight instance of exactly that pattern.
The payoff from running this audit cycle deliberately, as a structured cleanup called the Context Diet on 2026-04-13, was concrete. The always-on configuration dropped from 2,518 lines to 646, a 74% reduction. The pnpm ai:score result moved from 90 to 100 out of a 120-point rubric. The behavioral canary results moved from 10 of 14 total canary-style checks passing to all 14. Section F’s five behavioral prompts are the most targeted diagnostics; the other nine are distributed across the remaining sections of eval-ai-context. Less context, better behavior, the same counterintuitive finding the discipline article identified at the individual level, now confirmed at team scale.

What this changes
A CLAUDE.md maintained by one person over a few months is a configuration file. A system that six developers depend on, that accumulates 445 commits in a year, that has a sync pipeline and a CI gate and a 77-question audit skill, is infrastructure. It has owners, versioning, a review process, and a way to know when it breaks.
The analogy that keeps coming up internally is a database schema. You don’t edit the database directly. You write migrations, run them through a pipeline, and validate the result. CLAUDE.md is the same kind of artifact: a generated output from a defined source, maintained by a process, verified automatically.
The scaling pressure that makes this architecture necessary has a name. On IFTTD, Samy Lastmann described it: trying to run everything through enormous monolithic prompts works up to a point, but it does not scale, does not explain itself, and does not produce reliable measurement (ep 311). A system you cannot measure is a system you cannot maintain, and the source/output isolation described in this article is exactly what makes measurement possible: you know what changed because you know what you edited.
The same finding shows up at larger scale with the same conclusion. On IFTTD, Jocelyn N’takpe at ManoMano described running Claude Code across 250 developers for a year, and the clearest lever was also the most obvious one: keeping the CLAUDE.md current, because the more constrained the context, the more effective the agent (ep 346). Scale amplifies the signal in both directions.
Part four of this series identified the AI eval engineer as one of the roles the practice creates. At team scale, that role looks a lot like what the Context Diet process above describes: structured measurement, drift detection, behavioral verification, not a one-time setup but a continuous practice.
For how to avoid locking that practice to a single AI vendor, part six covers the portability layer: why native primitives outlast frameworks, and how the same sources generate different runtime configs without any model-specific content in the sources themselves.
From the field, via IFTTD episode transcripts: Samy Lastmann, ep 311 on why monolithic prompts do not scale; Zineb Bendhiba, ep 326 on behavioral non-regression; Frédéric Barthelet, ep 329 on statistical CI/CD for non-deterministic systems; Jocelyn N’takpe, ep 346 on instruction system maintenance at 250-developer scale.
If your team has crossed the threshold where AI configuration feels like infrastructure rather than a personal preference, I’d be curious where the tipping point was.