6/6 · Don't Build Your Moat on One Vendor's Runtime
Your AI instruction system is an asset. Locking it to one runtime is a liability. Native primitives, cc-bridge routing, one command to prove portability.
Context Engineering, a six-part series. You’re reading part 6: the portability. Part 1: the science · Part 2: the discipline · Part 3: the tooling · Part 4: the roles · Part 5: the team · Part 6: the portability (you are here)
| The risk | A well-built context system is an asset. Locking it to one runtime makes it a liability |
| The trap | Agent frameworks look like productivity. They’re often lock-in with extra syntax |
| Native primitives | 25 hooks, 57 skills with gated invocation, profiles, lexical skill routing |
| Model agnosticism | cc-bridge routes across providers. Same sources, different runtimes, no rewrite |
| The proof | pnpm ai:sync produces CLAUDE.md, .cursorrules, AGENTS.md, .codex/config.toml, and .mcp.json from one source |
Five parts in, this series has built an instruction system: sources isolated from outputs, modules shared across developer profiles, behavioral audit in CI, a sync pipeline as the operational backbone. The natural next risk is the one nobody mentions until it’s a problem. That system is now coupled to one vendor’s runtime, and any migration becomes a rewrite.
This part shows why building on native primitives from the start avoids that coupling, and how cc-bridge extends the same logic to the model layer itself.
The framework temptation
Google’s Agent Development Kit, CrewAI, LangChain: the appeal of agent frameworks is real. They abstract the orchestration layer, provide pre-built patterns for tool calling and memory, and get an agent running faster. For a prototype evaluated over a weekend, that’s a reasonable choice.
For a production system that six developers depend on, the framework tends to become a constraint. The abstractions that simplified the prototype now sit between you and the model’s native behavior. Debugging requires understanding the framework’s internal state before you can understand what the model actually did. Migrating to a new provider means adapting the framework bindings first. Adding a tool the framework doesn’t natively support means fighting the abstraction layer. The framework becomes the runtime, and the runtime becomes the lock-in.
On IFTTD, Maxime Thoonsen argued that taking agent development seriously means investing in fundamentals rather than framework syntax, and that software architecture skills become more valuable as tools multiply, not less (ep 307). The shell hook, the markdown module, and the YAML profile are all instances of a durable pattern: data-driven configuration with event-driven side effects. The specific tool that reads them can be swapped; the pattern stays.
The alternative is building on the platform’s native primitives directly: shell hooks, markdown files, YAML profiles. None of them require a framework layer, none of them introduce a dependency that outlasts the tool they were written for, and every one of them is readable by any developer without installing anything new.

Native primitives: hooks, skills, profiles
At Méthode Aristote, the Claude Code setup runs 25 shell hooks across the event lifecycle. The most visible is a global PostToolUse hook at ~/.claude/hooks/anti-ai-markers.sh. It fires after any Edit or Write call on .md, .mdx, or .txt files, strips code blocks and frontmatter before analysis, and checks for a defined set of detectable AI writing patterns: em dashes (U+2014), a curated list of overused adjectives in English and French that correlate with generated text, and mechanical transition phrases capped at one per text. A violation returns a decision: block signal and routes the feedback to a style guide file. No framework layer involved. The hook is a shell script, inspectable in two minutes, debuggable with bash -x.
The 56 procedural skills with disable-model-invocation: true follow the same logic. These are procedural skills: committing, shipping a PR, creating a release, running production database operations, scaffolding a new module. The model cannot invoke them on its own. Only the user can, via an explicit slash command. The reason is documented for the Sentry-related skills: prevents unsolicited automatic triage or fix. The same principle applies across all 57. Side effects that matter stay under human control, and nothing in the chain depends on a framework’s decision about when to trigger them.
BM25/lexical skill routing handles dispatch. A hook scores the incoming prompt against the skill library and routes to the best match. The target follow-rate is around 50%, measured weekly. That’s a calibration target, not a confirmed outcome yet, and the system gets sharper with each correction cycle. The approach is still worth naming because it replaces a framework’s intent classification with something inspectable: a scoring function over text, with results you can log and audit.
The practical consequence of building this way is that the entire behavioral layer is debuggable without framework-specific knowledge. You trace why Claude behaved a certain way from the event log, to the hook that fired, to the file it read, in three steps and without a debugger.
Model agnosticism: cc-bridge and neutral sources
The second half of portability concerns the model itself.
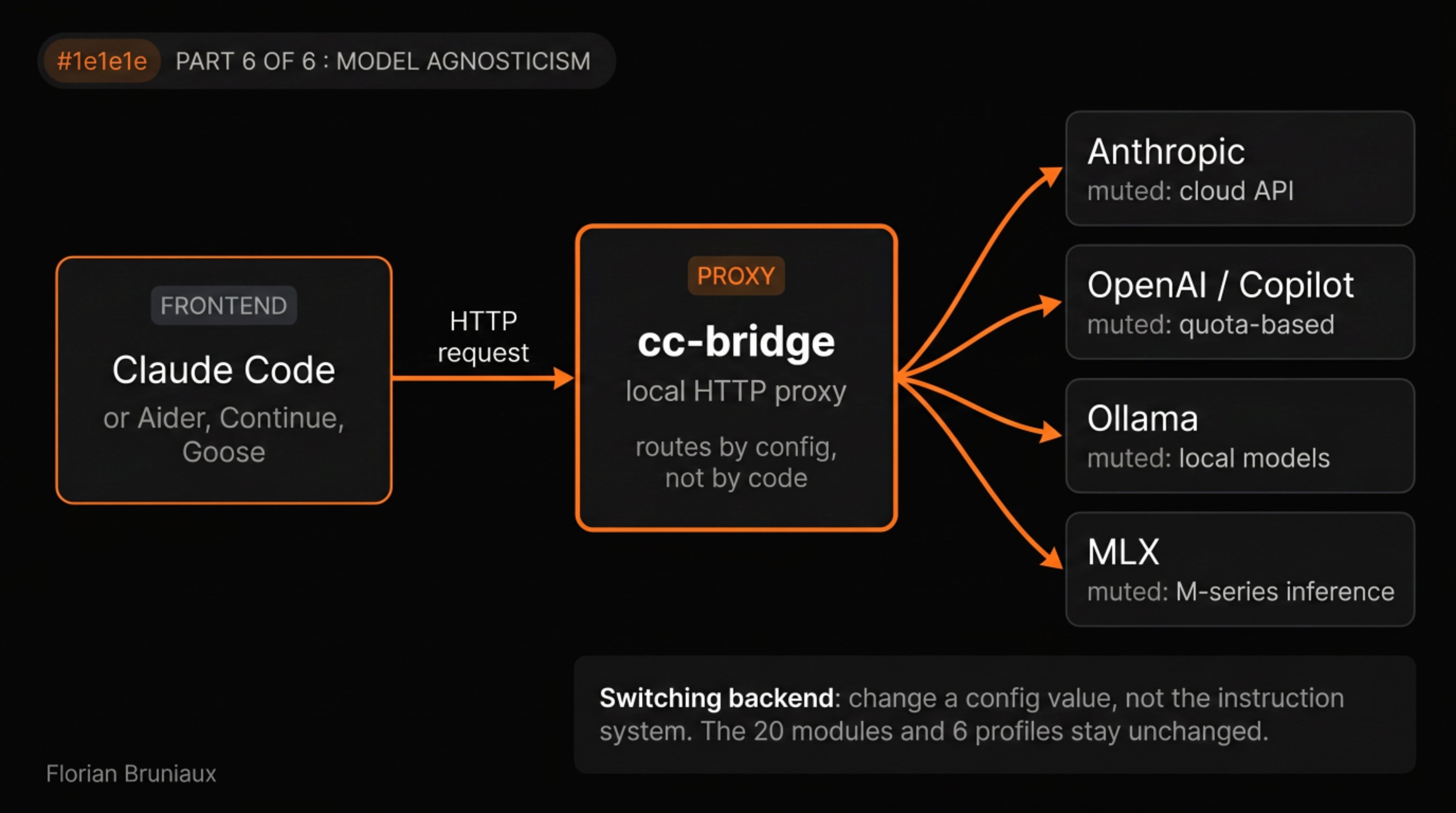
cc-bridge is a local HTTP proxy that sits between Claude Code and the model backend. Claude Code sends a request to cc-bridge, and cc-bridge routes it to whichever provider is configured: Anthropic, OpenAI (via GitHub Copilot quota), Ollama for local models, MLX for M-series hardware inference. The same setup works with Aider, Continue, and Goose as alternative frontends. Switching the active backend is a config change, not a code change.
The underlying principle goes back to how agent systems should be composed. On IFTTD, Samy Lastmann described model swaps as a microservice replacement: each model in a pipeline should be swappable without breaking the pipeline, and performance metrics should be defined before the swap rather than measured after (ep 311). cc-bridge makes that operational at the routing layer. The swap is a config change, and the behavioral canary checks from part five tell you whether the new model passes the same expectations.
This is a different concern from the API gateway layer described in part three. That layer, LiteLLM, Bifrost, and similar tools, intercepts API calls for cost compression and is structurally blind to Max and Pro subscriptions where no API key exists. cc-bridge doesn’t intercept for cost reasons. It routes for flexibility: testing a new model against the exact same instruction set the production model sees, falling back to a local model when a provider API is unavailable, or running a cheaper model on lower-stakes tasks without changing the configuration system that governs all of them.
The deeper portability is in the source format. The modules in doc/guides/ai-instructions/modules/ are plain markdown. They contain no Claude-specific syntax, no Cursor-specific directives, no framework-specific annotations. The profiles are YAML. The skeletons reference modules via {{module:name}} placeholders, a template convention the sync script resolves. None of this is coupled to any vendor.
The outputs are where runtime specificity lives. pnpm ai:sync produces CLAUDE.md for Claude Code, .cursorrules for Cursor, AGENTS.md for Codex and OpenAI agents, .codex/config.toml for Codex terminal, and .mcp.json for MCP server configuration.
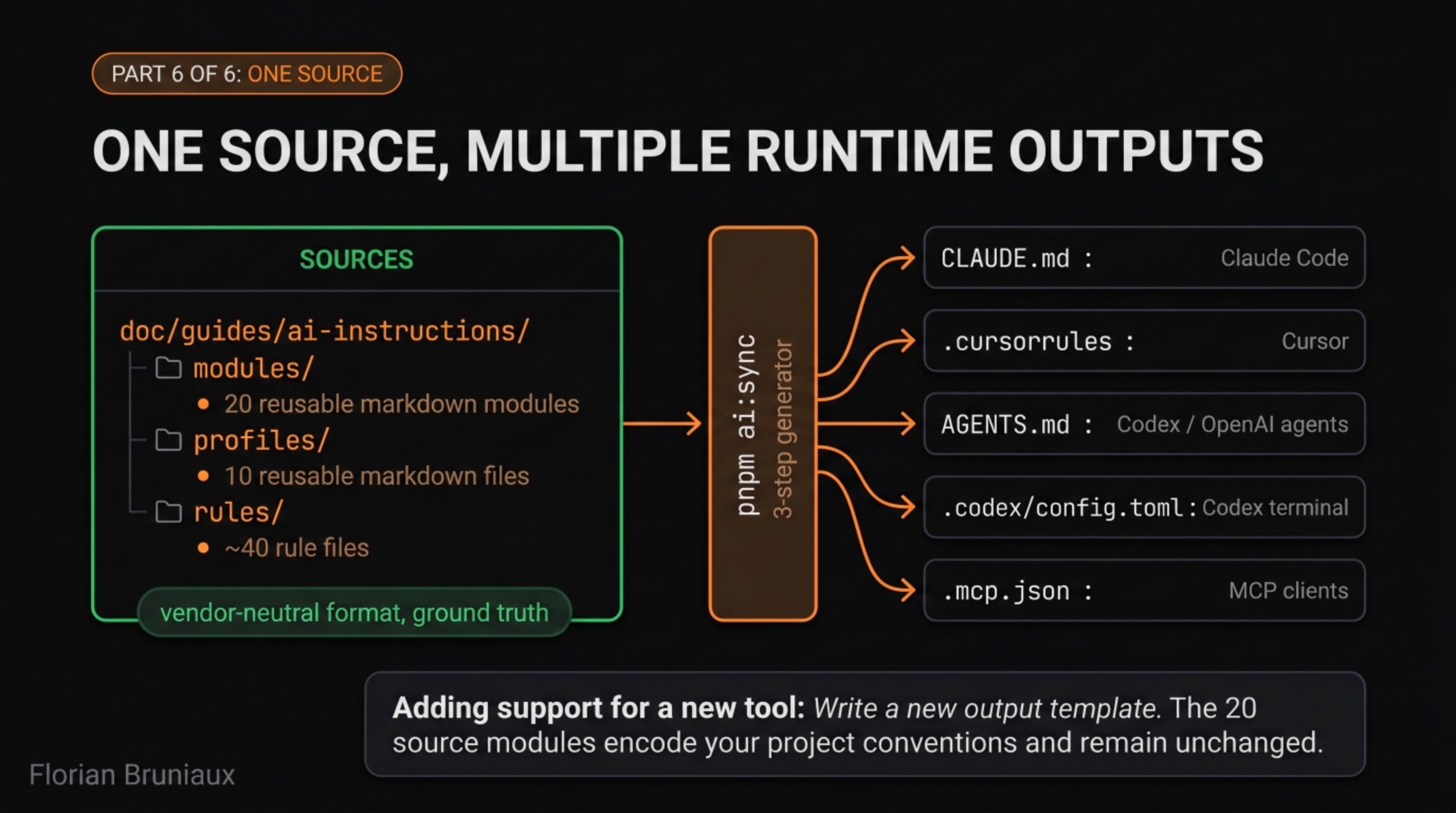
Each output file is formatted for its runtime. Each is generated from the same sources. Adding support for a new tool means writing a new skeleton and a new output step in the sync script. The sources stay unchanged, and the knowledge encoded in them carries over automatically.
The practical test is a straightforward one: if the model layer changed tomorrow, what would actually need to be rewritten? With this architecture, the answer is the output templates and the sync script, not the twenty modules that encode the project’s conventions, the six profiles that capture developer preferences, or the forty rule files that define the architectural guardrails. The instruction system survives the migration. That’s the whole point.
What survives
This series started with a measurement gap: same model, opposite outcomes, and the variable turned out to be how the context was built. It ends with a structural choice about how to build that context so it outlasts any single tool in the chain.
The durable decisions in the system described across these six parts are consistently the boring ones. Native shell hooks instead of framework callbacks. Neutral markdown modules instead of vendor-annotated config blocks. A sync pipeline instead of manual edits. These choices do not make the system faster to build. They make it cheap to maintain, easy to debug, and possible to migrate.
Which is exactly the kind of thing that looks obvious in hindsight and costs a rewrite to learn in production.
On IFTTD, Quentin Adam offered a governance principle that applies at the tooling level: for AI infrastructure, avoid annual subscriptions and leave developers to choose their own tools, because the field changes too fast for any commitment that outlasts a short billing cycle (ep 341). The instruction system described here applies the same logic at the configuration level. The sources are neutral, the sync is fast, and the outputs are generated: if the tool that reads them changes, only the output templates need updating.
Six parts, one through-line. Each article is self-contained; reading in order is the shortest path to the full picture.
| Part | Focus |
|---|---|
| 1/6 · The science | Why context degrades and the +67% / -19% paradox |
| 2/6 · The discipline | L0 to L5 maturity model, path-scoping, the verification loop |
| 3/6 · The tooling | Four-layer token map, RTK, the MCP tax, the Max/Pro blind spot |
| 4/6 · The roles | Context engineer, harness engineer, spec engineer, agent identity architect, AI eval engineer |
| 5/6 · The team | Profiles, modules, sync pipeline, behavioral audit in CI |
| 6/6 · The portability | Native primitives, cc-bridge, one source for every runtime |
From the field, via IFTTD episode transcripts: Maxime Thoonsen, ep 307 on fundamentals over framework syntax; Samy Lastmann, ep 311 on model swaps as microservice replacements; Quentin Adam, ep 341 on avoiding lock-in at the tooling governance level.
If you’ve migrated an AI-instrumented codebase from one model provider to another, I’d be curious what the hardest part was. My instinct is that the model was the easy part. Questions, a different take, or something you’ve measured that contradicts any of this? I read everything on LinkedIn.